Kubernetes @ Home 2 – LoadBalancing
Hello folks, after a long hiatus I'm back and am picking up my blog again. I've done a lot with my self-hosting projects, and figured it's time to start sharing what I've done.
Those who know me and readers here know that I firmly believe in kubernetes as a technology. Kubernetes is a way to run docker containers over many hosts, or nodes. It's a way that you can distribute your work over different computers and start abstracting away the concept of which specific computer is running your application. You start thinking of your computers as one giant “pool” of compute – a bunch of cores and RAM available to you to run workloads on. If you aren't familiar with kubernetes I invite you to read my previous post on k3s, a lightweight kubernetes implementation.
Installing k3s and running a pod like hello-world or nginx is fairly easy, but the learning curve continues it's trajectory upward from there. There are a few major hiccups from there, including storage (volumes), devices, configuration, and today's topic – Load Balancing.
Why Load Balance at home anyway?
This was my first question when setting up k3s. I run services for me, just me and the members of my household, why do I care about load balancing? It's a fair question too. In my professional life load balancing has a very different purpose – to spread load across many available pods to reduce bottlenecks – to balance the load. Makes sense, if I'm building a service for hundreds of thousands of concurrent users/requests having a single VM instance is an insane thought.
What is even worse is that in such a scenario you also have exactly zero redundancy. If that one point goes down for whatever reason your entire infrastructure is at risk. Load balancing isn't simply for distributing requests, but it can also be used to take unhealthy workloads out of the equation to distribute requests to known good workers.
That's professionally though – why at home?
Well, we aren't dealing with hundreds of thousands of requests, but we are dealing with at home servers running workloads. These are physical computers in the real world, with real world problems that can happen. It's easy in the mindset of cloud computing to forget about real-world problems with our computers, but they in fact real servers underneath all the “cloudy-ness”. If you're running at home, those real servers will break down: failed hard drives, bad ram, overheating, things will happen. Kubernetes can help keep your services online while you replace that failed hard drive.
K3s Defaults – ServiceLB
Out of the box with k3s you can immediately create a service. For today, let's define a simple pod and service to print Hello World.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
selector:
matchLabels:
app: hello-world
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: hashicorp/http-echo
args:
- "-text=Hello, World from Kubernetes!"
ports:
- containerPort: 5678
---
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: LoadBalancer
selector:
app: hello-world
ports:
- protocol: TCP
port: 80
targetPort: 5678
Let's call this example.yaml.
From here, we can go ahead and apply it using kubectl apply -f example.yaml. Now, to check to make sure everything is running, we can run these commands:
kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-world-84bf5c8b89-jvhpf 1/1 Running 0 2m39s
and kubectl get svc (shorthand for service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world LoadBalancer <<some internal ip>> <<hidden>> 80:31744/TCP 4m16s
What are we looking at here? First is our pods, we have a successful deployment (you can see the deployment too if you want, using kubectl get deployment) with 1 healthy pod up and running.
Breaking down what this is further, remembering our kubernetes basics: a deployment is a type of workload which will run our pods. So the first chunk of yaml is our actual application running. The pod is our containerized application. The second chunk is our service, which defines how we will access our pod.
The service is the interesting part here. At this point, with the default k3s settings you should see multiple IP addresses here under EXTERNAL-IP. Those IP addresses are the IP addresses of each of your nodes on your network. What does this mean?
First let's remember our types of services in Kubernetes.
- LoadBalancer – An external facing service, requests to this service are expected to come from outside of the cluster.
- NodePort – Exposes a port on a specific physical node of the cluster to a pod running on that specific node. If the pod is not present on that node, requests will be dropped.
- ClusterIP – An internal only service, only available to the cluster. It may not seem useful at first, except that the ClusterIP is the internal networking to the cluster. If two pods need to communicate with one another, the most common approach is a ClusterIP.
K3s comes bundled with ServiceLB, which is in itself a deployment running out of the box. It's actually running behind the scenes in the kube-system namespace. ServiceLB watches for incoming requests for LoadBalancers and then provisions a load balancer when it detects a new one by starting a daemonset to watch for incoming requests. If you remember, a DaemonSet is simply “One pod running on each node), so that means each node gets a pod running on it for your load balancer.
From then, it's pretty simple, each node has it's own “NodePort” service, which opens that port you requested to the DaemonSet pod, which then forwards the traffic to a local ClusterIP service.
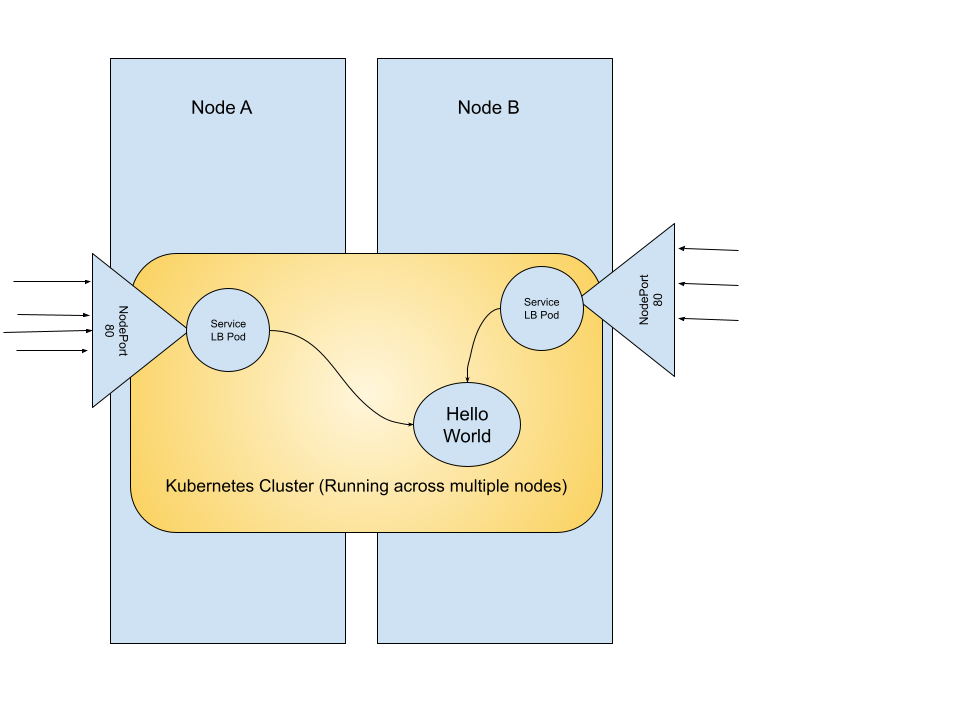
So what does this mean for our use case though?
Well, for one we do have a pod that's externally available from the cluster. You can right now navigate to any one of those IP addresses and you should be able to see our response.
curl http://<<ip address from service above>>
Hello, World from Kubernetes!
Great! So we're done, right? Well, kind of.
Are we actually load balanced this solution? Let's take a step back here with ServiceLB. We do have a service which you can access from any node, but if we assigned a DNS endpoint to it, what do we do?
If we assigned something like hello-world in DNS, which IP to we assign it to? The answer is any of them, any of those IP addresses would respond, but by doing so we just created a single point of failure in our network. (Okay, DNS is also a single point of failure, as the saying goes it's always DNS, it's always f*cking DNS, but for right now we technically have two points of failure if we count DNS).
This is because DNS will point to one node which will continue onto our service, but if we go back to the introduction, parts fail, nodes fail. That node, if it goes down or starts acting up, kubelet will take that node out of commission, but DNS is still pointing at that bad node. Meaning we have healthy pods somewhere in the cluster on other nodes, but they can't be reached because DNS is pointing at a faulty node. This means that yes our workloads have redundancy, but our services don't.
Personally, I ran this way for a few years. I wasn't aware of any better options on how to run a load balancer at home so I simply just dealt with it. I chose the most stable node that I could and pointed DNS there. This came to a head though not because of failing parts, but because of another issue – all of my traffic was going through one ethernet port.
Anytime an external service needed to talk internally, it would have to go to that single DNS endpoint, I couldn't split up the traffic at all. Some of you know I sometimes stream video games, and that's a lot of data – a lot of data sharing one single port with all of the other traffic within my cluster. Shouldn't I be able to split that out to other nodes? To balance the traffic?
MetalLB
So in my frustration I renewed my search for a better solution, and low and behold I found MetalLB. MetalLB was designed from the ground up to work with bare-Metal machines, and it does this beautifully.
MetalLB takes a different approach to load balancing physical machines (or VMs, whatever you may be working with). Instead of opening a port on every machine, MetalLB works directly with your networking stack at L2 layer of the networking stack.
It took a bit for me to wrap my head around it, but if you've ever forwarded a port for a video game or something on your router, you're probably familiar with the concept of DHCP or Static IP addresses. DHCP of course your computer reaches out to your router and asks for an IP address from the router's block of IP ranges, it receives the IP and is now addressable. The vast majority of people use DHCP and never know it.
Static IP addresses you manually decide that this computer is now “192.168.1.103” or whatever you the human decide, and the computer announces to the network that this physical machine is now that IP address. The router accepts it and allows traffic to it.
MetalLB works in the same way as Static addressing above, using ARP. The steps are:
1. Set up MetalLB, defining a list of “allowed” IP addresses that it can use
2. MetalLB manages which nodes will host which services. Each LoadBalancer can be assigned to any node (within taints/tolerations/etc).
3. MetalLB opens a NodePort service, same as ServiceLB, but only on the node that it is running on (instead of on every node).
4. MetalLB picks an IP address from the range you declared above
5. MetalLB declares to your router/network (via ARP) that the IP address is now available on that specific Node.
Your network/router is then the one doing the traffic “load balancing” in a way then. Traffic can go to any specific node on your cluster, but now MetalLB is managing which node is receiving the traffic.
Does this solve our problems then?
- Traffic is distributed across nodes? – Yes. Traffic for different LoadBalancers may now to to different nodes.
- Fault Tolerant? – Yes. If a node goes down, MetalLB will simply start a new endpoint on a different node, and updating the ARP table appropriately in your router. (There may be a bit of downtime while this happens, but it is tolerant and better than “Down until you fix it).
So let's see this in action.
Setting up MetalLB
Removing ServiceLB from K3s
(This is of course only if you're running K3s. If you're running something else check to see if you need to remove the default loadbalancer option)
First of all, we need to change k3s to not include ServiceLB. Otherwise these will conflict and you will have problems. This is done by going to your main node where you originally installed k3s and re-running the install script, but with the --disable-servicelb flag.
curl -sfL https://get.k3s.io | sh -s - --disable=servicelb
After doing this, I recommend restarting each node. They claim you don't need to, but with such a core change I definitely experience problems until I forced everything to stop and restart.
You can confirm it is no longer running by checking out the pods in the kube-system namespace. You should see nothing about servicelb anymore.
Installing MetalLB
I'll loosly say what I did here because you should absolutely follow the MetalLB Installation Guide instead, but I did have a couple hiccups while I installed.
As linked, I use Helm for my services and so I used Helm to install MetalLB. Which is good, I continue to be agnostic towards any specific technology, I can rebuild my entire cluster from scratch if I need to.
I did have to customize a bit though for installation. I created a custom values.yaml with these settings:
speaker:
excludeInterfaces:
enabled: false
controller:
logLevel: info
crds:
enabled: true
In our case the major one is crds, where we want MetalLB to create the Custom Resource Descriptors for it's types. This will help with the next step. To install MetalLB, now we just need to install it with helm:
helm repo add metallb https://metallb.github.io/metallb
I chose to install it to it's own namespace, metallb-system.
helm upgrade --install metallb metallb/metallb --values values.yaml -n metallb-system
Give it a few moments and you'll see the pods come online in that namespace.
Setting the allowed IP ranges
The last step of setup before we can run pods is to declare which IP addresses MetalLB can use for it's services. This is done using the CRD created above with the values.yaml. It creates a CRD called “IPAddressPool” and “L2Advertisement”.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: my-pool
namespace: metallb-system
spec:
addresses:
- 192.168.1.10-192.168.1.19 # Adjust for your your subnet
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: my-advertisement
namespace: metallb-system
spec:
ipAddressPools:
- my-pool
Change the IP addresses to whatever you have set in your router. It cannot be within the DHCP range of your router. My custom (and many routers) has always been that for IP addresses X.X.X.100+ is DHCP range (for random computers joining), but I reserve 1-99 as static ranges. Check your router and make adjustments as necessary.
Once you have set your IPs, either apply this manually with kubectl apply -f your-yaml-file.yaml or include it in whatever deployment plan you have.
Creating a LoadBalancer service with MetalLB
Now that you're installed, you can create LoadBalancer services!
In fact, your services might even be working right now. I say might because there is one very important alteration you'll need to make to your services now.
You see, while our traffic is distributed across nodes, there is currently nothing saying that the MetalLB's LoadBalancer pod running on one node must be running on the same node as your workload. Internally there may be a disconnect. I say may because by chance your workload might be running on the same node as the load balancer, but this is pure chance.
To fix this, we only need to add one line to our service from above:
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: LoadBalancer
externalTrafficPolicy: Cluster #Add this
selector:
app: hello-world
ports:
- protocol: TCP
port: 80
targetPort: 5678
This line here essentially tells MetalLB that pods will not be running on the same node for this service, and it creates a connection for us which will send traffic to our pods, even if they are running on other nodes. Think of it as an internal load balancer within our cluster.
If you now run kubectl get svc you should now see just one IP address for your LoadBalancer, something like this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world LoadBalancer <<Some internal IP>> 192.168.1.11 80:31744/TCP 67m
The External IP address should now be not one of your Node IP addresses, but one from the range you defined above. It's a bit weird since that IP doesn't actually point to any running machine, but if you curl that same IP you'll get..
Hello, World from Kubernetes!
Now simply go change your DNS to point to that IP address and no matter how many times you restart nodes, pods change around, as long as that range is available your DNS will be safe!
Summing up
That's it! Today we went from having a very bare-bones way to expose services on our cluster to having a robust, fault tolerant load balancing system. Not only is this going to make it easier for your own management of your cluster, but it has become fault tolerant and upgrade tolerant.
Your traffic is now abstracted away from your specific nodes and IP addresses, and is now declaring to your network where traffic should flow to, no matter what node is actually listening.
I think that's why I think MetalLB is such an interesting concept, because in first paragraphs I talked about how Kubernetes does a wonderful job at abstracting away from CPUs and Memory, but now it also is abstracting away the networking. Instead of keeping track of node IP addresses, you can now have your services declare where they are reachable, and I think that's pretty neat.
Stay tuned, next I'll be finally tackling Longhorn, or how you can abstract away your volumes as well, making local node storage that much easier to work with. Have fun out there!










 Please ignore the very messy wire-filled room, I still need to mount it
Please ignore the very messy wire-filled room, I still need to mount it
 An example configuration of a RAID configuration in BIOS
An example configuration of a RAID configuration in BIOS